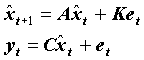(1)
By Palle Andersen - Structural Vibration Solutions A/S.
1 Introduction
In the traditional input-output modal analysis the estimation of modal parameters have been performed using a somewhat deterministic mathematical framework. One of the major hurdles for people of this traditional modal community to overcome, when turning to output-only modal analysis, is the switch of the mathematically framework. In output-only modal analysis the mathematically framework involves the use of statistics and introduction of concepts such as optimal prediction, linear system theory and stochastic processes.
The two general assumptions made in output-only modal analysis are that the underlying physical system behaves linearly and time-invariant. The linearity imply that if an input with a certain amplitude generates an output with a certain amplitude, then an input with twice the amplitude will generate an output with twice the amplitude as well. The time-invariance implies that the underlying physical system does not change in time. One of the typical parametric model structures to use in output-only modal analysis of linear and time-invariant physical systems is the stochastic state space system.
|
|
(1)
|
The first part of this model structure is called the state equation and models the dynamic behavior of the physical system. The second equation is called the observation or output equation, since this equation controls which part of the dynamic system that can be observed in the output of the model. In this model of the physical system, the measured system response yt is generated by two stochastic processes wt and vt. These are called the process noise and the measurement noise. The process noise is the input that drives the system dynamics whereas the measurement noise is the direct disturbance of the system response.
The philosophy is that the dynamics of the physical system is modeled by the n´n state matrix A. Given an n´1 input vector wt, this matrix transforms the state of the system, described by the n´1 state vector xt, to a new state xt+1. The dimension n of the state vector xt is called the state space dimension. The observable part of the system dynamics is extracted from the state vector by forward multiplication of the p´n observation matrix C. The p´1 system response vector yt is a mixture of the observable part of the state and some noise modeled by the measurement noise vt.
2 The Statistical Framework
2.1 Properties of stochastic state space systems
The state space model (1) is only applicable for linear systems that do not have time-varying changes of its characteristics. However, this is not the only restriction. The only way to obtain an optimal estimate of a state space model on the basis of measured system response, is to require that the system response is a realization of a Gaussian distributed stochastic process that has zero mean.
In other words, in the applied stochastic framework the system response is modelled by a stochastic process yt defined as
|
|
(2)
|
and the principal assumption is that the measured system response is a realization of this process. It is seen that this process is completely described by its covariance function Li. This means that if we can estimate a state space model having the correct covariance function this model will completely describe the statistically properties of the system response. An estimated model fulfilling this is called covariance equivalent. The estimator that can produce such model is called an optimal estimator.
Since the system response of the linear state space model is a Gaussian stochastic process it implies that xt, wt and vt all are Gaussian stochastic processes as well. Since the input processes wt and vt are unknown we make the simplest possible assumption about their statistical properties, which is to assume that they are two correlated zero-mean Gaussian white noise processes, defined by their covariance matrices as
|
|
(3)
|
The Gaussian stochastic process describing the state xt is also zero-mean and completely described by its covariance function
|
|
(4) |
Using (1) to (4) the following relations can be established
|
|
(5) |
The matrix G is the covariance between system response yt and the updated state vector xt+1. The covariance function of yt can also be expressed in terms of the system matrices as
|
|
(6)
|
There are two additional system matrices turns out to play an important role
|
|
(7) |
These are the extended observability matrix Gi and the reversed extended stochastic controllability matrix Di.
2.2 Optimal prediction
One of the most important parts of all estimation is the ability to predict the measurements optimally. In output only modal analysis this means to be able to predict the measured system response optimally. An optimal predictor is defined as a predictor that results in a minimum error between the predicted and measured system response. If the system response can be predicted optimally it implies that a model can be estimated in an optimal sense.
Recall that the state vector xt completely describes the system dynamics at time t. In order to predict the system response yt optimally it is necessary to start by defining an optimal predictor of xt. Now assume that we have measurements yk available from some initial time k = 0 to k = t-1. Collect these measurements in a vector
|
|
(8)
|
In the Gaussian case the optimal predictor of xt is then given by the conditional mean value
|
|
(9) |
So, the optimal predictor of xt is defined as the mean value of xt given all measured system response yk from k = 0 to k = t-1. The difference between ![]() and xt is called the state prediction error and is defined as
and xt is called the state prediction error and is defined as
|
|
(10) |
This error is the part of xt that cannot be predicted by ![]() .
.
In order to predict the system response a similar conditional mean can be formulated for yt
|
|
(11)
|
The last part of this equation is obtained by inserting (1) and assuming that vt and yk from k = 0 to k = t-1 are uncorrelated.
2.3 The Kalman filter.
The two predictors (9) and (11) are related through the so-called Kalman filter for linear and time-invariant systems, see e.g. Goodwin et al. [6]
|
|
(12)
|
The matrix Kt is called the non-steady state Kalman gain and et is called the innovation and is a zero-mean Gaussian white noise process. Defining the non-steady-state covariance matrix of the predicted state vector![]() as Pt the Kalman gain Kt is calculated from
as Pt the Kalman gain Kt is calculated from
|
|
(13)
|
The last of these equations is called the Ricatti equation. The Kalman filter predicts the state ![]() on the basis of the previous predicted state
on the basis of the previous predicted state ![]() and the measurement yt. The covariance Q of the innovations et can be determined from the last equation in (12) as
and the measurement yt. The covariance Q of the innovations et can be determined from the last equation in (12) as
|
|
(14)
|
Given that the initial state prediction is![]() and the initial state prediction covariance matrix P0 = 0 and assume that we have measurements yk available from k = 0 to k = t-1, then this filter is an optimal predictor for the state space system (1) when the measurements yt are Gaussian distributed.
and the initial state prediction covariance matrix P0 = 0 and assume that we have measurements yk available from k = 0 to k = t-1, then this filter is an optimal predictor for the state space system (1) when the measurements yt are Gaussian distributed.
2.4 The innovation state space system.
At start up the Kalman filter (12) will experience a transient phase where the prediction of the state will be non-steady. However, if the state matrix A is stable the filter will enter a steady state as time approach infinity. When this steady state is reached the covariance matrix of the predicted state vector![]() becomes constant, i.e. Pt = P, which imply that the Kalman gain becomes constant as well, i.e. Kt = K. The Kalman filter is now operating in steady state and is defined as
becomes constant, i.e. Pt = P, which imply that the Kalman gain becomes constant as well, i.e. Kt = K. The Kalman filter is now operating in steady state and is defined as
|
|
(15)
|
The steady state Kalman gain is now calculated from
|
|
(16) |
The last equation is now called an algebraic Ricatti equation. Assuming all matrices but P is known this equation can be solved using eigenvalue decomposition, see Aoki [2] and Overschee et al [1].
If the last equation in (15) is rearranged the following state space system is obtained
|
|
(17)
|
This system is called the innovation state space system. The major difference between this system and (1) is that the state vector has been substituted with its prediction, and that the two input processes of (1) have been converted into one input process – the innovations. This state space system is widely used as model structure in output only modal analysis, see e.g. Ljung [3] and Söderström et al. [4].
3 The Stochastic Subspace Identification Framework
The Kalman filter defined in the last section turns out to be the key element in the group of estimation techniques known as the stochastic subspace techniques.
From (17) it is seen that if sufficiently many states of (1), let’s say j states, can be predicted, i.e. ![]() and
and ![]() , then the A and C matrices can be estimated from the following least regression problem
, then the A and C matrices can be estimated from the following least regression problem
|
|
(18)
|
This is a valid approach since the innovations are assumed to be Gaussian white noise. Since A and C are assumed to be time-invariant this regression approach will be valid even though the predicted state ![]() and
and ![]() originates from a non-steady state Kalman filter. So the fundamental problem to solve in the stochastic subspace identification technique is to extract the predicted states from the measured data. To show how this is performed, consider the state space system in (1) and take the conditional expectation on both sides of both equations to yield
originates from a non-steady state Kalman filter. So the fundamental problem to solve in the stochastic subspace identification technique is to extract the predicted states from the measured data. To show how this is performed, consider the state space system in (1) and take the conditional expectation on both sides of both equations to yield
|
|
(19)
|
Now assume that a recursion is started at time step q. Inserting the first equation in (19) recursively into itself i times and finally inserting the result the last of the equations in (19) leads to the following formulation
|
|
(20) |
This equation shows the relation between the initial predicted state ![]() and the prediction of the free (noise free) response of the system
and the prediction of the free (noise free) response of the system ![]() . By stacking i equations on top of each other the following set of equations are obtained
. By stacking i equations on top of each other the following set of equations are obtained
|
|
(21) |
By introducing the vector oq as the left-hand side and noticing that the first part of the right-hand side is equal to the extended observability matrix Gi we actually obtain the following expression for the predicted states
|
|
(22) |
The matrix Gi-1 is actually the pseudo-inverse of Gi. This equation shows that if we can estimate Gi and oq for several values of q, we can in fact estimate the predicted states for several values of q as well.
3.1 Estimation of free system response.
In this section we will focus on the estimation of the predicted free response ![]() . We will estimate a set of vectors Ot and gather them column by column in a matrix O. In order to predict the system response a conditional mean similar to (11) can be formulated.
. We will estimate a set of vectors Ot and gather them column by column in a matrix O. In order to predict the system response a conditional mean similar to (11) can be formulated.
|
|
(23) |
This conditional mean is the prediction of the future system response yi+q given the past system response from time t = i+q-1 down to t = q. This conditional expectation is only an approximation of (11) since the conditioning vector stops a time t = q and not t = 0. The approximation is only good if i is sufficiently high. For zero-mean Gaussian stochastic processes this conditional mean can be calculated by, see e.g. Melsa et al. [5].
|
|
(24) |
Since the error ![]() is zero-mean and uncorrelated and is independent of the conditional mean
is zero-mean and uncorrelated and is independent of the conditional mean ![]() and the conditioning vector yqi+q-1 the conditional mean (24) is also called the orthogonal projection of the vector yi+q onto the vector yqi+q-1.
and the conditioning vector yqi+q-1 the conditional mean (24) is also called the orthogonal projection of the vector yi+q onto the vector yqi+q-1.
In order to estimate all elements of oq we need to extend (24) to allow estimation of ![]() to
to ![]() in one operation. This is done by using (8) to extend the conditional mean
in one operation. This is done by using (8) to extend the conditional mean ![]() in (24) to the following
in (24) to the following ![]() . This results in the following equation for oq
. This results in the following equation for oq
|
|
(25) |
In the last equation a new ip´ip matrix Lk is introduced for simplicity. This matrix is defined as
|
|
(26) |
Incidentally, the matrix Li is also equal to
|
|
(27) |
As seen in (18) we need a bank of predicted state estimates ![]() for q = i to q = i+j-1 for a sufficiently large value of j. To estimate these state in one operation based on the approach in (25) we need to define the following two matrices Oi and Yp as
for q = i to q = i+j-1 for a sufficiently large value of j. To estimate these state in one operation based on the approach in (25) we need to define the following two matrices Oi and Yp as
|
|
(28) |
|
|
(29) |
The index p in (29) signifies that the matrix contains system response of the past compared to the system response we are predicting. Since we assume that the system response is stationary, i.e. that ![]() , equation (25) can easily be extended using (28) and (29) to yield
, equation (25) can easily be extended using (28) and (29) to yield
|
|
(30) |
With this equation the first of the two major tasks in the stochastic subspace identification technique has been fulfilled.
If the extension in (30) is carried on to (22) we obtain the following relation
|
|
(31) |
The matrix![]() is a bank of predicted states and is defined as
is a bank of predicted states and is defined as
|
|
(32) |
As seen the matrix Oi only depends on system response and system response covariance, and can therefore be estimated directly from the measured system response. In Overschee et al. [1] a method based on the QR decomposition is presented (For more on the QR decomposition, see e.g. Golub et al. [7]). This method estimates Oi directly from the measurements without explicit need of the covariance estimates. By using that method the stochastic subspace identification techniques can surely be called data driven identification techniques.
Since the matrix Oi is the same no matter which data driven identification technique that is used this matrix is also referred to as the Common SSI Input Matrix.
3.2 Estimation of the extended observability matrix.
In order to estimate A and C in (18) what remain is to estimate the extended observability matrix Gi as shown in (22). It is actually the estimation of this matrix that can be done in different ways and results in that several stochastic subspace identification techniques exist. In this section we will treat the matter in a generalized way by introducing two so-called weight matrices that takes care of the differences between the techniques. In chapter 4 we will show how to choose these weight matrices in order to arrive at different techniques.
The only input we have for the estimation is still only the matrix Oi, i.e. only information related to the system response. The underlying system that has generated the measured response is unknown, which means that we do not know the state space dimension of underlying system. What this means can be seen from equation (31) that defines the matrix Oi as the product ![]() . The outer dimension of Oi and therefore also of
. The outer dimension of Oi and therefore also of ![]() is ip´ j. However, the question is what the inner dimension of this product is. The inner dimension is exactly the state space dimension of the underlying system.
is ip´ j. However, the question is what the inner dimension of this product is. The inner dimension is exactly the state space dimension of the underlying system.
So to find Gi the first task is to determine this dimension. We determine this dimension from Oi by using the Singular Value Decomposition or SVD, see e.g. Golub et al. However, before taking the SVD we pre- and postmultiply Oi with the before mentioned weight matrices W1 and W2 which are user-defined. Now taking the SVD of the resulting product yields
|
|
(33) |
Assuming that W1 has full rank and that the rank of W2 is equal to the rank of YpW2, the dimension of the inner product ![]() is equal to the number of non-zero singular values, i.e. number of diagonal elements of S1. From the last two equations of (33) we see that Gi is given by
is equal to the number of non-zero singular values, i.e. number of diagonal elements of S1. From the last two equations of (33) we see that Gi is given by
|
|
(34) |
The non-singular n´ n matrix T represents an arbitrary similarity transform. This means that we have determined the extended observable matrix except for an arbitrary similarity transformation, which merely means that we have no control over the exact inner rotation of the state space system.
As seen the state space dimension is determined as the number of diagnonal elements of S1, and Gi is found on the basis the reduced subspace of W1OiW2. For these reasons it is no wonder why the estimation techniques are called subspace identification techniques.
3.3 A general estimation algorithm.
Independently of the choice of weight matrices W1 and W2 the estimation of the system matrices can be done in the general way presented in this section. This approach presented here is not the only one, but in the current context properly the most obvious choice. In Overschee et al. [1] two other approaches are also described. The estimation can be divided into three parts.
3.3.1 Data compression.
Assuming that N samples of measured system response are available the user needs to specify how many block rows i the matrix Oi should have. As seen from (33) the maximum state space dimension depends on the number of block rows and will be ip, where p is the dimension of the measured system response vector yt.
It should be remembered that the maximum state space dimension corresponds to the maximum number of eigenvalues that can be identified. It should also be remembered that i is the prediction horizon and as such depends on the correlation length of the lowest mode to be identified. Oi are the estimated using (30). However, in order to estimate the matrix![]() we also need to estimate the matrix Oi-1 since
we also need to estimate the matrix Oi-1 since
|
|
(35) |
This can be proven by proper substitutions in the above equations, see also Overschee et al. [1]. Oi-1is estimated by deleting the first p rows of Oi.
3.3.2 Subspace identification.
Pre- and post multiply the matrices W1 and W2 which are dependent upon the actually identification algorithm. Determine the SVD (33) of W1OiW2, and calculate the extended observability matrix Gi. Gi-1 is obtained from Gi by deleting the last p rows.
3.3.3 Estimation of system matrices.
Now we have all the information available that is needed in order to estimate a realization of the innovation state space system defined in (17). Estimate the predicted states![]() and
and ![]() using (31) and (35), and set up the following matrix of measured system response
using (31) and (35), and set up the following matrix of measured system response
|
|
(36) |
Solve the least squares problem
|
|
(37) |
where ![]() is the pseudo inverse of
is the pseudo inverse of ![]() . The steady state Kalman gain K is estimated by the following relations. First estimate the reversed extended stochastic controllability matrix Di from (27)
. The steady state Kalman gain K is estimated by the following relations. First estimate the reversed extended stochastic controllability matrix Di from (27)
![]() (38)
(38)
The covariance matrix G can then be extracted from the last p columns of Di. Estimate the sample covariance matrix L0 rom e.g.
|
|
(39) |
Estimate the Kalman gain K in (16) by solving the algebraic Ricatti equation in (16) first. Finally, estimate the covariance matrix Q of the innovations using (14).
4 Some Stochastic Subspace Identification Algorithms
As mentioned in section 3.2, the only significant difference between the different stochastic subspace algorithms is the choice of the weight matrices W1 and W2. In this chapter we will focus on three algorithms, the Unweighted Principal Component algorithm, the Principal Component algorithm and the Canonical Variate Analysis algorithm.
4.1 The Unweighted Principal Component algorithm.
The Unweighted Principal Component algorithm is the most simple algorithm to incorporate into the stochastic subspace frame work. As the name says it is an unweighted approach which means that both weight matrices equals the unity matrix, see Overschee et al. [1]
|
|
(40) |
The reason is that this algorithm determines the system order from the left singular vectors U1 of the SVD of the following matrix
|
|
(41) |
Since we have chosen the weight to be unity the covariance of W1OiW2 equals
|
|
(42) |
This show that covariance (42) is equal to (41) which means that (41) and (42) has the same left singular vectors. From (34) we see that the extended observability matrix is determined as
|
|
(43) |
This algorithm is also known under the name N4SID.
4.2 The Principal Component algorithm.
The Principal Component algorithm determines the system matrices from the singular values and the left singular vectors of the matrix Li. This means that the singular values and left singular vectors of W1OiW2 must equal the singular values and left singular vectors of Li. To accomplish this the weight matrices are chosen as
|
|
(44) |
The covariance of W1OiW2 now equals
|
|
(45) |
This shows that the singular values and the left singular vectors of (45) and Li are equal. From (34) we see that the extended observability matrix is determined as
|
|
(46) |
Even though it appears that (46) is equal to (43) they are not. We must remember that the SVD has been taken on different matrices due to the different weights.
4.2 The Canonical Variate Analysis algorithm.
The Canonical Variate Analysis algorithm, see Akaike 74,75, computes the principal angles and directions between the row spaces of the matrix of past outputs Yp and the matrix of future outputs Yf. The matrix of past outputs Yp is defined in (29), and the matrix Yf is defined in a similar manner
|
|
(47) |
The principal angles and directions between the row spaces of Yp and Yf are determined from the SVD of the matrix, see Overschee et al. [1]
|
|
(48) |
Comparing with (30) we obtain the same covariance matrix of (47) and W1OiW2, and therefore also the same principal angles and directions between the row spaces of Yp and Yf , if we choose the following weights
|
|
(49) |
The covariance of W1OiW2 now equals
|
|
(50) |
The covariance of (47) is given by
|
|
(51) |
We see that the covariance matrices of W1OiW2 and (48) are equal. In the above it has been used that ![]() . Finally, we see that the extended observability matrix is determined as
. Finally, we see that the extended observability matrix is determined as
|
|
(52) |
Since L0 is a byproduct of the determination of Oi this estimator is very easy to implement into the common framework.
References
Overschee, P. van & B. De Moor: Subspace identification for linear systems – Theory, Implementation, Applications. Kluwer academic Publishers, ISBN 0-7923-9717-7, 1996.
Aoki, M.: State Space Modeling of Time Series. Springer-Verlag, ISBN 0-387-52869-5, 1990.
Ljung, L.: System Identification – Theory for the user. Prentice-Hall, ISBN 0-13-881640-9, 1987.
Söderström, T. & P. Stoica: System Identification. Prentice-Hall, ISBN 0-13-127606-9, 1989.
Melsa, J. L. & A.P. Sage: An Introduction to Probability and Stochastic Processes. Prentice-Hall, ISBN 0-13-034850-3, 1973.
Goodwin, G.C. & K.S. Sin: Adaptive Filtering, Prediction and Control. Prentice-Hall, ISBN 0-13-004069-X, 1984.
Golub, G.H. & C.F. Van Loan: Matrix Computations. 2nd Ed. The John Hopkins University Press, ISBN 0-8018-3772-3, 1989.